Firebender supports the most powerful coding models:
Changing models
Select model with dropdown:
Models can misreport their name and version at runtime. This is because they are often trained on data generated by previous versions of themself or other models.
Context Windows
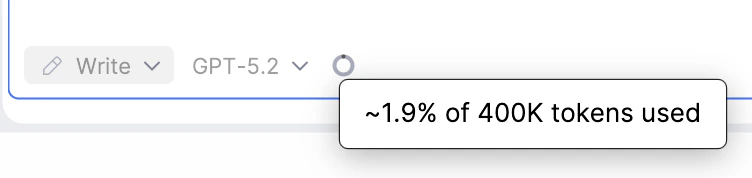
A context window is the maximum span of tokens (text and code) a model can consider at once. The more prompts, files, and responses in a session, the more context is consumed.
Firebender intelligently summarizes and shifts context around to balance speed and accuracy.
An estimate of tokens used is provided:
Default Model
Default Model: Firebender attempts to select the best model for each task based on request complexity, model availability, rate limits.
Custom model controls and restriction
Deep Links
jetbrains://idea/firebender/chat?model=claude-haiku-4-5-20251001
Read more: Deep Links
Commands
Configure in firebender.json with "model": "claude-haiku-4-5-20251001".
Read more: Commands
Organization restrictions
Companies may not want to support certain models or providers, and can restrict what models their team has access to. Team admins will need to add later models to the list when new models are released by providers.
Get started: Model restrictions
Model Pricing
Firebender plans include usage at model provider API rates. For example, $30 of included usage on the Developer plan will be consumed based on your model selection and its price.
Usage limits are shown in editor based on your current consumption. All prices are per million tokens.